




I hope you enjoy reading this blog post.
If you want to get more traffic, Contact Us


Click Here - Free 30-Minute Strategy Session
Be quick! FREE spots are almost gone for this Month. Free Quote

Are you looking for some SEO hacks that are worth implementing?
Well, then you are at the right place.

Click Here – Free 30-Minute Strategy Session
Be quick! FREE spots are almost gone for this Month
Anyone who is planning to make the most out of SEO will always be on a constant look out for some quick harmless hacks.
We are also no exception to this mindset.
We love to identify new ways that make our lives much simpler and better.
Today, we are here to present you with a technique, which is one of our absolute favorite too.
This is one of the most legitimate SEO hacks, which you can begin right away without having to wait.
Here is a way to drastically increase the fruitfulness of your SEO efforts by exploiting one of the most natural aspect of your website.
Well, to give you a hint, this is an aspect that rarely gets talked about and it is certainly not hard to implement either.
Got it?
Yes, it is your robots.txt file. Also known as the robot exclusion standard or the protocol.
This particular tiny teeny text file is an essential part of any website on the world wide web, which most of the people do not even recognize.
Now, this element is made to work with the search engines.
But, the surprising fact is that it is a crucial part of SEO that is waiting for you to tap into it.
We have seen clients over clients trying everything possible to make their SEO efforts work.
So, when we say a lot can be done by making some changes to their little text files they just find it hard to believe.
While there are numerous SEO tactics that are extremely simple and less time consuming, we will not be wrong if we say that this one is the easiest of them all.
The best part is, you do not require any sort of technical expertise to make the most out of what the robots.txt has to offer.
If you are able to locate the source code of your website, then you are all set to use this trick.
Once you are ready, just follow along with us.
We will clearly show you how to make modifications to your robots.txt files, such that the search engines will end up loving it.
Before getting an answer to this question, it is essential for you to know why robots.txt even matters.
Also referred to as the robots exclusion standard or protocol, robots.txt files are nothing but text files that help web robots (mostly search engines) in choosing the correct pages on your website to crawl upon.
Having said that, it also tells these robots about the pages on which it is not supposed to crawl.
Let us assume that a particular search engine is about to visit a specific website.
Now, before it crawls over the target web page, it checks the robots.txt to get the required instructions.
There are a variety of robots.txt files. Let us now take a look at some of these different types and understand how they look like.
Let us assume, a search engine ends up finding the following robots.txt file type:

Now, this is the standard basic structure of any robots.txt file.
In the image above, the asterisk, which is present after the phrase “user agent”, implies that this robots.txt file is applicable to all the web robots visiting that particular site.
Above all, the aim of all your SEO strategies is to easily get the search engines to crawl your website, thereby increasing your ranking.
This is exactly where the secret of this SEO hack lies.
If you do not agree with us, just go back and check it yourself. We are sure you will be surprised.
When search engines crawl on your website, they will crawl over every single page on your website.
If you have several pages, then the search engine bot will take quite some time to crawl on all the pages.
This time lapse can have a negative impact on your page ranking.
Well, this is because Google search engine bots have something called “crawl budget”.
This can be broken down into two parts:
1. Crawl rate limit
2. Crawl demand
The main priority of Googlebot is crawling, while ensuring that the user experience is not degraded when they are visiting your site.
This is referred to as the “crawl rate limit”.
The factor limits the maximum possible fetching rate for any given site.
In other words, it is the total number of parallel connections that Googlebot uses to crawl over a site along with the time it waits between the fetches.
Let us assume that the crawl rate limit has not yet reached. Do you think the Googlebot will be very active?
No, not until there is a demand from indexing.
This is known as crawl demand.
Well, getting back to the point, crawl budget is the number of web pages that a Googlebot would want to and can crawl.
So, any guess what your aim should be?
Yes, you got it. You should ensure that the crawl budget is well spent by the Googlebot for your website.
Simply put, Googlebot should crawl on all your most valuable web pages.
Now, according to Google, there are certain factors that can have a negative impact on the crawling and indexing of a website.
These factors are also referred to as low-value URLs and they can be categorized into the following:
3. Soft error pages
4. Low quality and/or spam content
5. Hacked pages
6. On-site duplicate content
7. Proxies and infinite spaces
8. Session identifiers and faceted navigation
If you waste server resources on such pages will reduce crawl activity on the pages that are actually valuable.
This in turn will hugely delay the process of discovering good content on your website.
Coming back to the robots.txt. . . .
By creating appropriate robots.txt pages, you will be able to guide the search engine bots and prevent them from crawling on low-quality pages.
When you successfully guide the search engine bots to only crawl over the most useful content on your website, your site will be crawled and indexed only based on that content.
Basically, you will prevent the crawler from wasting the crawl budget by crawling on unimportant pages on your website.
Therefore, by correctly using robot.txt, you will be able to tell the search engine bots to wisely spend their crawl budget.
This is what makes robots.txt file so crucial in the SEO context.
Taken aback by the capability of robots.txt?
Well, you should be. Such is its power.
Now, let us understand how to identify and use it.
If you want to get a quick view of your robots.txt files, then we have an extremely easy way for you.
In fact, the method we are about to reveal can be applicable to any website.
So, you can just take a peek on the files of the other websites and know what they are up to as well.
All that you should do is to simply type out the base URL of the website you want into the search bar of your website and then add robots.txt at the end.
One of the following three situations will arise:
1.You will find your robots.txt file
2.You will find an empty file
3.You will see a 404 error message
Now take a moment to view the robots.txt file of your own website.
If you get a 404 error message or find an empty file, this means you will have to fix this.
However, if you find a valid file it is mostly set to the default settings, which were made when the site was created.
This method can be particularly useful to look at the robots.txt files of other websites.
Once you are thoroughly aware of the robots.txt, it can be a great exercise.
Now, let us move towards making changes to your robots.txt files.
This steps hugely depends on whether or not your have a robots.txt file.
You can find out the same by carrying out the method mentioned above.
The bad news is if you do not have this file, then you will have to create one.
Open a note pad or any other plain text editor, again ensure that you choose a plain text editor.
This is because using programs such as Microsoft Word will pose the threat of inserting additional codes into the text.
One of the best options to consider that is also free is editpad.org. Also, in this article, we will be using this.
If you already have a robots.txt files then all that you have to do is to just find it in the root directory of your website.
Well, if you are not too comfortable with poking around the source code, then the chances are that you might find it difficult to find the editable version of the robots.txt files.
Generally, you can locate the root directory by just visiting the hosting account website.
Here, you should first login and then head towards the FTP or the file management section of your website.
Upon following these steps, you should be able to see the following or something similar to this:
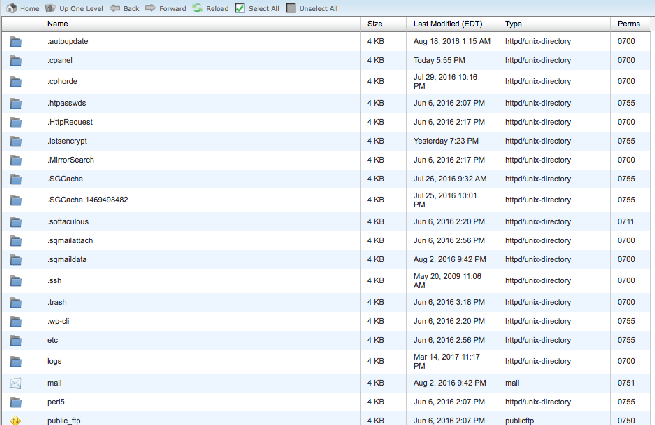
In this, identify your robots.txt file and then open it to make modifications. Get rid of all the text but do not delete the file.
Note: If you are leveraging WordPress, you will be able to see the robots.txt file as soon as you visit robots.txt/yoursite.com, but you cannot find it in the files.
This is mainly because WordPress tends to create virtual robots.txt files when there are no robots.txt files in your root directory.
Did this happen to you too?
Well, then in that case you will have to make a robots.txt files.
You can easily make a new robots.txt file just with the help of a plain text editor that you are comfortable with.
Just make sure you are using a plain text editor.
However, if you are already having a robots.txt file, then just ensure that you have deleted all the text without deleting the file.
Coming back, to begin with, you should first become familiar with the syntax that is used in the robots.txt files.
Google provides a good explanation for some of the basic robot.txt terms.
Now, we will explain in detail how to set up you robots.txt files.
Once this is done, we will then look at how you can customize it for better SEO.
Okay, let us begin by setting up a user agent term.
You should set it up such that it can be applicable to all the web robots.
This can be done by adding an “asterisk” at the end of the user agent phrase. Refer the image below:

Next, you will have to type out “Disallow”, but wait. . .after this make sure you do not type out anything, like the image below:

When there is nothing after the term disallow, you will be directing the web robots to crawl over your entire website.
At this point, everything on your website will be a fair game.
If you have been following the steps, then your robots.txt file should look somewhat like this:

We know, it looks extremely simple, but already these two lines are doing a lot.
While you will also be able to link the XML site map, it is just not required. However, if you prefer to include it, then here is the format for it:
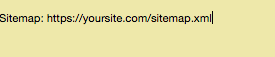
Now, this is how a basic robots.txt file would look like.
You should now take it to the next level, by transforming this simple file into a major SEO booster.
The kind of optimization you should be doing for your robots.txt files hugely depends upon the type of content that you have on your website.
There are numerous ways to leverage robots.txt files to your advantage.
We will look at some of the common ways to leverage it.
Note: Using these files to block the pages from the search engines is not appropriate. It is a big NO.
One of the major uses of these files is maximizing the crawl budget of the search engines by guiding them and preventing them from crawling the parts of your website, which are visible to the users.
For instance, just try visiting the robots.txt files for any site.
You will realize that most of the sites will disallow their login page.
Refer the image below:
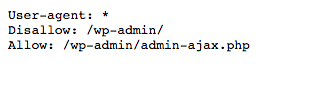
This is because login pages are only used for logging into the backend of any given website.
So, it just does not make sense to get the search engine bots to crawl over pages like these.
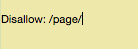
In this way, you can use similar commands to disallow certain web pages and prevent the search engine bots from crawling over them.
Once you write the command disallow, add the part of that particular page’s URL (only the part that is present before “.com”), in between 2 forward slashes.
Refer the image below:
Are you now wondering what types of pages should you exclude from being indexed?
Well, that is a good question.
Following are some of the most common pages that can be excluded from being indexed.
Although duplicate content is something that is not accepted, there are a couple of instances in which these types of content are necessary and are also accepted.
Let us say, you have created a printer-friendly version of a specific page.
In this case, technically you will have a duplicate content.
So, in such cases, you can guide the search engine bots and prevent them from crawling the print friendly version of your web page.
This can also be helpful to split test pages having the same content yet different designs.
We know we know. . .as a marketer “thank you” page will be one of your most favorite pages because this is the page that gives you some new leads.
Isn’t it?
However, it is a known fact that some of the thank you pages are easily accessed by the Google.
So, this is a bad news because it means that the users can access pages like these without going through the process of lead capture.
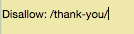
Well, the good news is you can ensure only the qualified leads will be able to see these pages by blocking the thank you pages.
So, if your “thank you” page is found at a particular URL – https://yoursite.com/thank-you/ – blocking this page in your robots.txt file would look like the following:
As there are no universal rules to specifically disallow these pages, your can be rest assured that this file will be unique to your website.
So, you can go with your judgment here.
However, there are two more directives that you are supposed to know, they are:
By now you are very well aware of the “disallow” directive, which we have been using.
The fact is that it simply does not prevent the indexing of your web page.
It only means that even if you disallow a particular page, you cannot completely prevent it from ending up in the index.
That is something that you would not want.
This is exactly where your no index directive can come to your rescue.
It works in tandem with the disallow directive to ensure that the search engine bots do not index or visit some of the pages.
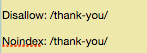
Once you do this to a particular page, you can be ensured that page will not appear in the search engine result pages.
However, the nofollow directive will be implemented slightly differently simply because it is not a part of your robots.txt file.
Yet, nofollow directives continue to instruct the web robots, hence the concept remains the same with the only difference being the place where it occurs.
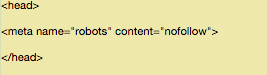
So, just identify the source code that you would want to modify and ensure that you will be in between the tags “<head>”.

Now, after this, just paste the following line:
“<meta name=”robots” content=”nofollow”>”
Once done, it should look like this:
One thing you have to be very sure here is that you have not placed this line in between any other tags.
This is also a great option for thank you pages because web robots do not crawl the the links that take to exclusive content such as lead magnets,
However, if you would like to add both the nofollow as well as the noindex directives just use the following code:
<meta name=”robots” content=”noindex,nofollow”>
Doing this will provide the web robots with both the directives together.
Finally, do not forget to test the robots.txt files you just created. This helps you to ensure that everything is valid and is working in the right way.
Google offers free robots.txt tester, which is a part of the Webmaster tools.
You can just sign up into your webmaster account, choose the property and finally click crawl.
You will then view “robots.txt Tester”, choose this option.
If you already have some code in the box, make sure you delete it and then replace it with your robots.txt files.
Next, choose the option “Test”. If you get “allowed”, it means that your file is valid.
You can then upload the robots.txt files to the root directory.
Now, you have a powerful file in your hand, which will help you to boost your visibility.
We love to share all the small SEO hacks we are aware of, which can give you a great advantage in numerous ways.
By doing this you are not just helping yourself, you are also assisting your visitors.
When you help bots to wisely spend their budget on crawl, they will display your page in the best possible way in the search engine result pages.
This only means that you get better visibility.
Besides, it is a one-time setup, where you can still go ahead and make small changes from time to time without any hassle.
Whether you are doing it to your first website or to your 10th website, this trick will make a great difference to your SEO.
Now that you have a whole new SEO tactic in hand, please try and let us know how helpful our post was.
In case of queries and feedback, feel free to drop it in the comments section below.
Be quick! FREE spots are almost gone for this Month



LEAVE A REPLY