




I hope you enjoy reading this blog post.
If you want to get more traffic, Contact Us


Click Here - Free 30-Minute Strategy Session
Be quick! FREE spots are almost gone for this Month. Free Quote

We have come across several clients who still have misconceptions about XML sitemaps.
SEO, being the most powerful way of promoting your website, a small error can leave you behind the competition.

Click Here – Free 30-Minute Strategy Session
Be quick! FREE spots are almost gone for this Month
Be it your keywords, meta-description, Header Tags, Robots.txt, Sitemaps or Alt tags, the functionality and optimization must be taken care before adding to your pages.
Of course, they are powerful and this calls for a better understanding of how XML sitemap works.
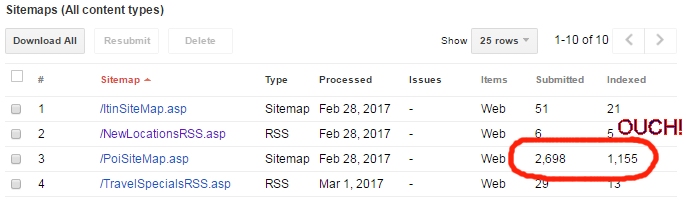
Millions of websites are created everyday and 50% of them go unnoticed due to indexation.
The websites are hardly crawled hence they aren’t picked in the search results.
The common misconception is that XML sitemaps get your pages indexed.
Let us remind you that your pages are indexed not because you requested Google to but, for the very reason that Google found your pages to be worthy enough to be indexed.
Google has certain criteria to crawl the pages and if your pages are fulfilling them, your site is sure to be indexed.
Having said that, you must indicate Google that you have pages that need to be crawled.
You can do it by submitting an XML sitemap to Google Search Console.
It also signals Google that the pages are important and must be crawled.
A standout amongst the most widely recognized slip-ups that individuals’ make is the lack of consistency to inform Google about a page.
A website is an ongoing process and changes are a part of it. You might have added a few pages to your site and the content might be half-finished.
You definitely wouldn’t want it to be crawled by Google. Thus, “noindex,follow” is to be added to the page.
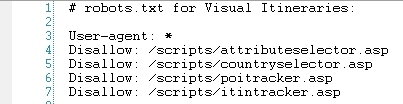
If you have blocked a page in robots.txt and still have incorporated it in an XML sitemap, you’re being really dumb.
Also don’t make a mistake of including a page in an XML sitemap and then setting the meta robots as “noindex, follow.”
Google has strict guidelines to check the quality of the website.
Let’s say you have 100 pages added to your website but, are those all relevant?
Absolutely Not!
There might be just 5-6 pages that would be completely informative and would fulfill all the criteria of Google.
You would definitely want only the most relevant pages to be presented to the users.
Each site has a specific number of “utility” pages that are valuable to clients, however not really content-type pages that ought to arrive pages from design: pages for imparting substance to others, answering to remarks, signing in, and recovering a lost secret word would be given weight-age by Google.
On the off chance that your XML sitemap incorporates landing pages, logging in details, retrieving a lost password, replying to comments, what are you conveying to Google?
Pretty much that you have no idea concerning what constitutes great content on your site and what doesn’t!
Let’s say you have a site with 400 pages and only 175 out of them have awesome content.
You can just overlook the remaining 225 pages.
Consider that 175 pages are crawled by Google. Google will review these pages and if 100 pages fall in Grade A, 50 in B, and remaining 25 in B+, your site is great and can be shared with the users.
Imagine that you have submitted all the 400 pages to be indexed via the XML sitemap.
Google reviews all the 400 pages and finds out that more than 250 pages are of Grade F.
The remaining 100 pages are of Grade D and the last 50 are of Grade E.
Overall, it’s an indication that your site sucks and surely Google wouldn’t want to share a site like this to the users.
Google will consider all the pages as important that you have submitted in your XML sitemap.
In any case, since it’s not in your XML sitemap, doesn’t really imply that Google will overlook those pages.
You could have thousands of pages with less content and they still might be indexed.
It’s vital to do a site search and find out pages that you have forgotten to submit.
Also, you must check the average graded pages and make the necessary changes to upgrade the level.
There’s an imperative however inconspicuous distinction between using meta robots and using robots.txt to counteract indexation of a page.
Using meta robots “noindex, follow” permits the link equity heading off to that page to stream out to the pages it connects to.
On the off chance that you obstruct the page with robots.txt, you’re simply flushing that down the bin.

When would you want to use the robots.txt?
Maybe when you are facing the crawl bandwidth issues or when Googlebot is investing heaps of energy getting utility pages, just to find meta robots “noindex, follow” in them and bailing out.
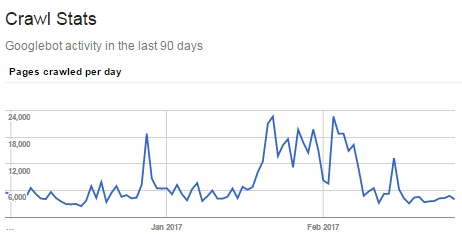
On the off chance if you have a large number of such pages and Googlebot isn’t getting to your important pages, at that point you may have to use robots.txt to block them.
You might be thinking that you have to manually sync XML sitemap with meta robots to all lakhs and lakhs of pages that your site has.
Well, that’s slightly difficult to do.
However, there’s no compelling reason to do this manually. XML sitemaps don’t need to be static records.
Truth be told, they don’t need a .XML augmentation to submit them in Google Search Console.
You can set up the meta robots index or noindex in the page itself.
Have some XML sitemaps query? Want us to help you out? Comment below!
Be quick! FREE spots are almost gone for this Month



LEAVE A REPLY